The cloud-native landscape is rapidly evolving, with 85% of global organizations expected to be running containers in production by 20251. To continue to meet business goals while enhancing business agility and streamlining operations, you need a holistic, comprehensive data management solution for your entire data estate.
Commvault has always been at the forefront when protecting new technologies, with containers and Kubernetes no different. We have built broad support for protecting applications running on a Kubernetes cluster and their data. Every CNCF (Cloud Native Computing Foundation) certified Kubernetes distribution is supported, and via the CSI (Container Storage Interface) framework, we also support a wide range of storage providers on Kubernetes, ensuring you have complete cloud-native data protection, managed through the simplicity of a single data management solution.
In this new release we bring two new key capabilities to Kubernetes data protection:
- Full Cluster & namespace level protection.
- Protecting the ETCD.
Recap
Commvault allows users to easily onboard a Kubernetes cluster into the Commvault Command CenterTM aka the single pane of glass for all your data protection, data management and data lifecycle needs.
Commvault defines a Kubernetes application as anything that is a pod or a collection of pods viz: Deployments, ReplicaSets, Statefulsets etc. and their associated components as inferred from their application yamls.
To break that down a bit, when we look at an application like a Deployment, we look at its config. spec. and discover any PVCs (Persistent Volume Claims), Secrets, ConfigMaps and other associated entities. All these together constitute an application.
A user can browse an onboarded cluster for applications, select and group them together into an “Application Group” based on backup SLAs (Service Level Agreements), retention needs or any other criteria.
Users can add applications to Application Groups in a few diverse ways:
- Browse and pick all applications in a namespace or multiple namespaces.
- Select specific applications.
- Use dynamic discovery rules: e.g.: Select applications that match a particular label selector or name etc.
Dynamic discovery is especially useful where a backup administrator can have the devops teams set label selectors on their applications and be guaranteed specific protection SLAs (Service Level Agreements).
Backup jobs run at an Application Group level and use the content rules to discover existing and newly created applications and their resources on the cluster at run time and perform backups. PVCs are backed up using CSI when available or alternatively Commvault can attach to PVCs directly using ReadMany semantics if CSI is not available.
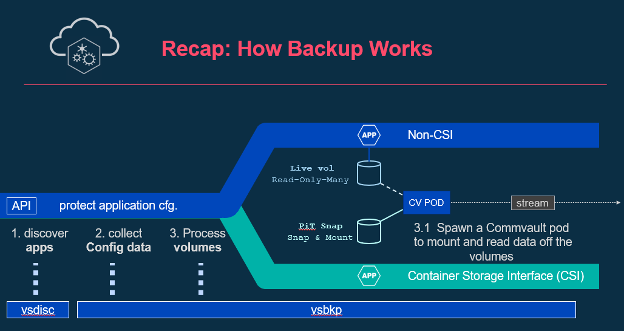
A diagram that illustrates how it all happens.
With Commvault, restoring an application or its data can be done at various granular levels:
- Application level restore: An entire application along with its associated resources and data can be restored in one shot.
- Application files: An application’s data (or portions thereof) residing on PVCs can be restored piecemeal without having to restore the entire application.
- Application configuration files: Configuration files constituting an application can be restored as files so that a user can manipulate them before applying them to the cluster.
Enhancements
It is now time to talk about the exciting new enhancements, delivering complete Kubernetes protection, and included in Platform Release 2022E.
1. Full Cluster Protection
With this feature we have added an easy button for the backup admin to press: Pick up everything on the cluster please. Thank you very much!
Everything in the cluster including cluster-scoped resources is picked up when configured in this manner.
Additionally, namespaces that are freshly discovered at backup time are also automagically included.
Backup admins must no longer select individual namespaces or applications within a namespace to be fully protected.
2. Namespace Level Protection
In addition to an entire cluster, users can now choose to backup an entire namespace i.e., applications (and their resources) and any unreferenced resources within the namespace (we call them orphans).
Also, users are now able to restore namespaces in their entirety while still retaining the various granular restores explained above.

3. Protecting the etcd.
etcd is a distributed, replicated database that Kubernetes uses to store the cluster configuration. The image below illustrates the usage of etcd in a typical Kubernetes cluster.
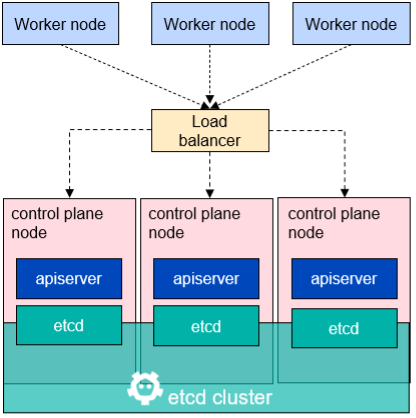
Each control plane node has a replica/copy of the etcd.
Losing/corrupting these copies can wreak havoc on a Kubernetes administrator’s day (or week).
Since etcd is replicated across the master nodes in a Kubernetes cluster, traditional solutions attempt to protect etcd by protecting the master nodes. This is often achieved by deploying solutions on those cluster nodes to protect the etcd locally. This is unwieldy and cumbersome at best because it separates protection for the applications running on the cluster and the protection for the cluster state into two very disparate mechanisms. Protecting application state and protecting cluster state go hand in hand and separating the two can lead to inconsistencies esp. when recovering from a disaster.
Commvault now seamlessly integrates etcd protection right alongside application and full cluster protection into the Command Center. A user simply needs to enable a toggle on the cluster to protect etcd and select an SLA. That is, it! Really! (See the snapshot below)

With these enhancements we have developed a holistic comprehensive solution for your Kubernetes Data Protection needs and, integrated it into our Commvault Command Center so you can simplify management of your entire data estate from a single interface. No wonder Commvault continues to be an outperformer in this space.
Reference
1 – Forbes – A CxO’s Guide To Container Monitoring


